TL;DR it’s not promising.
Introduction
Hardware tends to move slow. And for good reason. When you spend millions of dollars in capex, you want to eliminate as much risk as possible.
Still, the demand just keeps increasing. I (knock on wood) don’t foresee the world needing any less amount of hardware, and thus, any less amount of verification. And there’s really not that many verification engineers, period. That doesn’t even get into segmenting into all the niches of verification that exist. Personal anecdata– the rule of thumb for when I started in the industry was 2 verif guys per 1 design guy. I definitely feel like that ratio is decreasing, and not for want of things to do, especially as more hardware startups pop up that often can’t have swaths of teams like the incumbents have.
To address this productivity gap, lots of academics and some industry folk are harnessing ⭐AI⭐ to try and take my job. Here is one such conference. Give the papers a skim if you’d like to follow along.
There are 3 significant components of a verification methodology. 1) is the stimulus generation 2) checkers and 3) coverage analysis. Every single one of these steps has dozens of existing toolchains supporting it and major teams of people working on it. And I’d certainly argue that #3 is probably the most most most important, for without it, you have zero feedback as to the quality of #1 and #2.
I say it’s “just three components” but in reality, there’s tons of iteration and cross-referencing between the three. Here’s a typical thought process.
Oh dear, we have a bug escape, why did this assertion not catch it? Did I write it wrong?
Hm come to think of it, we’re not seeing as many e.g. branch mispredicts on our coverage runs, shouldn’t our stimulus be making lots of them?
Oh, our stimulus does have a lot, I can see it in waves. Oh my cover point misses counting these cases
Ah now that I do see the cover point being hit, I see my assertion was incorrectly coded. I forgot to account for xyz signal
Ah it’s taking forever for stimulus to reach this case. Let me code up an injector/driver/irritator (or whatever term).
On basically every line of this above thought process there’s like 5 tools duct taped together to make it all work. The biggest question I’d have if I were to genuinely try to incorporate some AI workflows is– what are the alternatives?
I’m not optimistic. Let’s look at some papers. Jump to the discussion if you’d like and feel you’re well versed in the state of academia.
Papers and Analysis
Paper One: Generating Assertions
LLM-assisted Generation of Hardware Assertions
The main overarching investigations of the paper– 1) Can LLMs generate hardware assertions? 2) How do LLMs perform, and scale, with various prompts?
This paper essentially tries to tackle Step 2 of the methodology I outlined above. The DUT under question is some code from HAC@DAC, containing known vulnerabilities, so the generated assertions are dedicated towards these security applications, but security assertions tend to be a subset of normal assertions anyways so it’s still sufficient for the two questions the paper addresses. Also worth noting is that they use code-davinci-002, i.e. basically ChatGPT-3.5.
The authors tweak and play with various prompts to get the checkers they want, “want” meaning that the generated checkers catch the same fails compared to when a “human” writes them. They tweak with 1) how descriptive the actual prompt is 2) an “example” for the LLM to follow 3) a “preamble” for syntax and 4) varying amount of actual DUT source code.
I’m not impressed.
To address question 1)– yes, it can. 5% of the time.
To address question 2)– In the best case scenario– that is, with a lot of prompting, a lot of source code, etc.– they obtain 80% “correctness” for quite simple checks. At the point that you’re basically writing the assertion in providing the context, you might as well write the assertion yourself instead of fighting this alleged “productivity improvement” tool.
For example– Take what they call “BM1”, an assertion inside a register lock module that checks that the register data is not modified when “lock” is set. Under best case conditions, the generated assertions are correct 60% of the time. 60%! This is a two signal assertion, and it fails almost half the time.
Consider also the fact that, oftentimes, security often spans across multiple units. Scaling is critical. And while the paper does comment that providing additional context to the prompt improves results, this is a little bit of a no-brainer. E.g. the notion that going from “assert that the register is not changed if it is locked” → “assert that at every positive edge of clock, the value of the data register is same as its value in the previous clock cycle if the value of the lock signal in the previous clock cycle is 1” provides significant improvements (if you consider going from 5% → 50% significant) is rather comical.
Paper Two: Generation Assertions 2
– The principal idea behind this is to generate assertions based on the spec itself, i.e. extending Paper One’s idea of playing with the prompting and just making the spec itself the promp. The problem here is that specs are oftentimes quite buggy.
They say in the paper itself there’s 3 steps to their workflow– 1) extracting relevant information from the spec itself 2) aligning signal names between the spec and the precise Verilog 3) gaining high confidence in the accuracy of the generated SVAs. Note by accuracy they mean accurately describing the spec, not “confidence” in coverage or such.
It’s a very similar methodology to paper one, though one significant difference is that they essentially feed in the SystemVerilog spec.
One issue with the paper specifically is that there’s no great presentation of their results. They may claim “89% of generated assertions are functionally correct” but really they only look at I2C spec. Looking at their Github, there’s just the PDF of the specs they’ve analyzed, and the “golden rtl” reference implementations they have, so why do they only have on Table 2 only an analysis focused on I2C?
Furthermore, “functionally correct” is evaluated by running FPV tools alongside the generated assertions. While I understand this is a PoC, I also feel that proposed alternatives need to handedly beat the incumbents. This just shows parity, and for a rather simple design at that.
Speaking of simplicity, issue/observation #2 is that these assertions generated are still incredibly simple. As with many things in academia, it’s pretty straightforward when the spec is just an I2C protocol, or even an AES core which similarly has been a rigorously defined and studied problem. But if this fine-tuned LLM ran something on e.g. BOOM, I’d be impressed.
Question #3 I have with this paper (that is discussed briefly in their concluding remarks) is how we would have any confidence in the coverage of the generated assertions. While, sure, this is not a paper-specific question, and you could certainly say this is just out-of-scope for the paper, the paper is also like only 8 pages and not terribly technically dense. I’d really think that discussion of coverage is critical for a properly fleshed out evaluation.
Overall, though these results are not outright depressing, and the newest idea compared to the previous paper is to simply toss in the IEEE spec to its context, the paper feels a little lacking. I also think that reducing the “prompting” to the spec will just lead to more not less fighting with the LLM.
Paper Three: Stimulus Generation
LLM4DV: Using Large Language Models for Hardware Test Stimuli Generation
The main investigation of this paper is using LLMs for stimulus generation. Essentially, following the three core components of the methodology I mentioned above, the LLM replaces step one, generating test cases by prompting it. They set up a coverage monitor (I’m not sure how they evaluate coverage but let’s suspend disbelief for now) and simply iterate and mutate the prompting based on the bins a specific prompt hits. They play around a little with how exactly it mutates, including optimizing for a lower number of prompting (since more prompting == more money) but the core framework is rather straightforward.
And the results are pretty depressing. See for yourself.
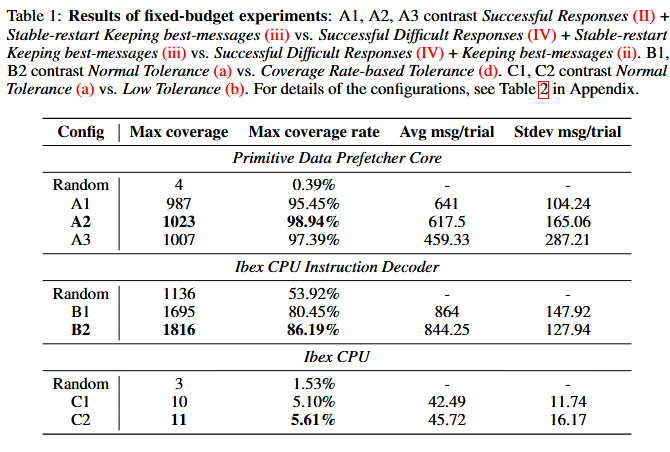 .
.
To me, this highlights the main challenge in code generation overall, and specifically using LLMs, and maybe issues in academia. Sure it’s all rather “easy” in smaller toy models (e.g. claimed coverage in this data prefetcher is 98%) but the moment it’s scaled up to a (not even terribly complicated) “real-world” CPU it all comes crashing down. Oftentimes the secret sauce is not in simply coming up with the idea, but the ability to execute it at a large scale.
Paper Four: Design Generation
VeriGen: A Large Language Model for Verilog Code Generation
I think this is a good paper, with results that really feel like a nail in the coffin to me about the direction of LLMs in academia. If nothing else, I think the conclusion is an incredibly realistic take on its results and I recommend reading that alone.
I want to slightly move away from verification and discuss a design paper. In this paper, the design code itself is generated, and they use a suite of LLMs from 355M parameters to 16B parameters (MegatronLM, to CodeGen-16B, to code-davinci). As in previous papers, they obtain much better results compared to vanilla models by feeding in basically all Github Verilog code and dozens of Verilog books (much more corpus than just the IEEE SystemVerilog spec I suppose). The designs in question are basically textbook problems they’ve gathered, feeding in the problem question to the LLM.
They evaluate the generated code by 1) writing their own testbench, for simple problems like a basic counter, and 2) uploading the solution to HDLBits who already have various problem sets and verification suites. Fair enough! Why reinvent the wheel.
There are a couple of principal questions they investigate (at least, that I find interesting). 1) To what degree does fine-tuning (i.e. throwing more Verilog data) improves correctness and 2) How does scaling parameter size improve correctness?
I’ll let the results speak for themselves. Red lines are mine for emphasis
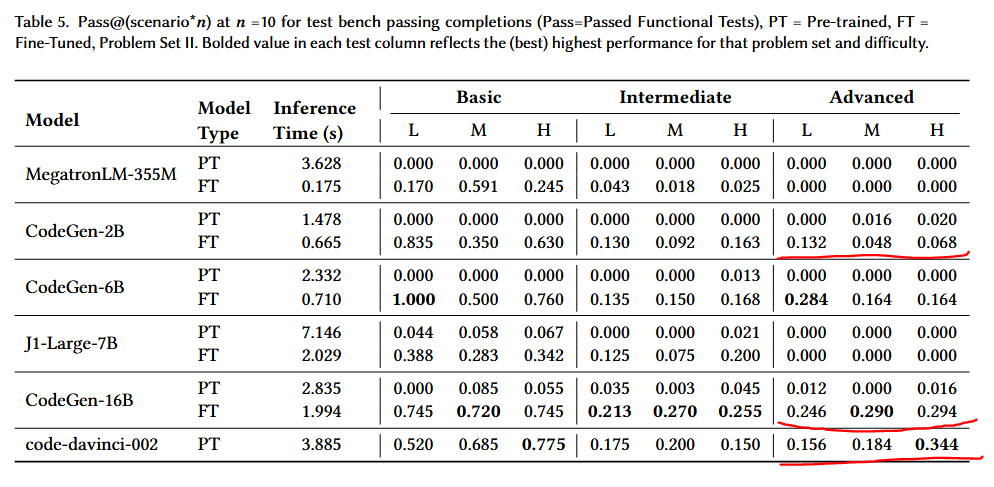
These numbers are basically an average of the “correct” generated designs, with varying complexity of the problem design (basic, intermediate, advanced). FT and PT mean fine-tuned with a bunch of Verilog data, and off-the-shelf. L M and H are meant to indicate the level of detail they had in the problem descriptions.
I want to only focus on the “Advanced” portion and also the three red underlines. It’s rather expected that quality improves when Verilog corpus are used, and I suppose there’s minor scaling effects from e.g. CodeGen-2B –> CodeGen-16B, but I still find it rather disappointing.
Firstly, I find it slightly disingenuous to be using “averages”– in fact, if you look at Fig 9 in the paper, not a single LLM managed to generate a passing design for “Game of Life”.
Second, while I understand a certain proposal might be that “skeleton code” can be used for a designer to then verify (a cited claim for all generated code, honestly) that very term– “skeleton code”– is a human definition that’s prone to errors. Is a multiplexer “skeleton”? Is an adder “skeleton”? Is a CPU “skeleton”? By saying that a designer can “just clean up” skeleton feels so incredibly hand-wavey about how real design iteration works.
Thirdly, and frankly, the results just aren’t very good. Under best case conditions, these “advanced” problems are only correct 30% of the time. The results are even sometimes worse in bigger models.
The authors themselves even comment slightly that there’s more to finangling LLMs than just having bigger context or more parameters (from the conclusion)–
Furthermore, the problem of error localization poses a unique challenge. As shown in the prompt description Fig. 19, the error was not localized and instead embedded subtly within the code’s structure. This required the LLMs to have a deeper comprehension of the code beyond the local context, something which they currently struggle with.
…
This reinforces our observation that while LLMs have significantly improved in generating compilable “skeleton” code, achieving functionally correct code, especially in complex problems, continues to be a challenge.
I’d be even more especially concerned if the assumed use case is a designer generates this code, signing off on it, and causes the DV engineer to miss the “subtly embedded” error.
Paper Five: Benchmark for Evaluating LLMs
RTLLM: An Open-Source Benchmark for Design RTL Generation with LLMs
If you’re still following along, I’ve commonly said there’s no good measure of scale for these LLMs. Every paper is just coming up with their own tasks, be it from textbooks, or some random Github repos.
Enter this paper. They pose a series of tasks and categorize how GPT-3.5 and GPT-4 handles 1) correct syntax generation and 2) correct functionality.
I found this table’s presentation to be rather straightforward, which I greatly appreciate. For each model, the “Syntax” column is the number of times the task had correct syntax (out of 5 trials), and the “Func” column is whether some generated design passed some tests they wrote.
The “SP” column is what they called “self-planning” which is just a fancy word for employing a chain-of-thought technique in their prompts.
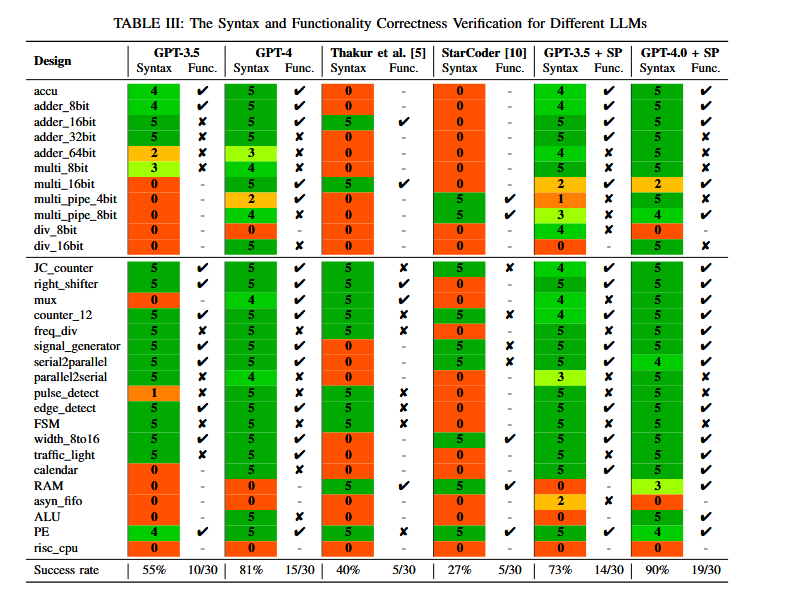
Honestly, I don’t think this is a good suite, but it’s a start. One misleading thing about it is the amount of what I’d call “textbook problems”. A huge deal of them are essentially present on Github already, and when 90% of them are under 100 lines, there’s definitely some grade inflation. The only problem with any reasonable complexity is the CPU (which btw isn’t uploaded on their Github?) of which none of them can do it.
The tests they wrote are also incredibly directed, but whatever. It’s a paper, I get it, nobody cares about verification, and the notion of a framework is enough for the scope of this paper so they can just punt “better verification” to future work or some jazz.
One thing I definitely want to point out is the occasional degradation in specific tests between GPT-3.5 SP and GPT-4 SP. As the model increases, the adder_32bit has functionality broken, and asyn_fifo fails to generate anything. I’ve said multiple times that reliability is quite critical, and I’m not confident here.
Minor Paper Summary
The first two papers has some notion of coverage and/or completion, but having a metric of “does this compile” is almost an insulting metric, and the coverage metrics they do have are incredibly poor with a not even terribly complicated design. Sure, we can have a single module assertion on some bus protocol, but it scales horrendously.
The third paper proposes some stimulus framework and also throws some coverage numbers at us (though still not sure what the numbers mean). Much like with the checkers, it scales horribly, even according to the authors’ own metrics, and on a not-terribly-complicated CPU either.
The fourth paper I looked at investigated the code generation capabilities itself. You can probably guess horrible scaling, and saying nothing about the correctness of the code, it doesn’t even get noticeably better as LLM size increases.
Finally, the fifth one proposes some benchmark tasks and minorly runs GPT-3.5 and GPT-4 just to demonstrate how it scales. Personally, I’d like to see more CPU oriented tasks, but whatever. Judging by the Google Scholar citations, it definitely has some mild popularity.
Discussion
Much of the secret sauce is figuring how to do things at scale.
Scale is overrated, you might argue, and that we need some level of bootstrapping. Certainly academia is supposed to provide novel ideas and proof-of-concepts, and push the boundary of human knowledge just an infinitesimal amount, but do these? These aren’t ablation studies or comprehensive frameworks besides throwing in different corpusi (corpuses?) and prompt astrology engineering. Which might be novel info in certain domains, but belongs more on engineering blogs, and frankly not deserving in hardware. The interesting cases are in that last 1%, in finding this “subtly embedded” error, not just in getting a synthesizable block.
Anyways, this isn’t a criticism of these particular papers, but a reflection of my pessimism of LLM research as a whole and their use in the hardware world. Much like this super good read, I think there’s certain fundamental things about LLMs that can’t be fixed by just increasing the context window and increasing parameter size.
Additionally, in all the papers I’ve seen, I really haven’t found many addressing improving coverage, something I find key to the whole methodology. I could imagine a flow where the cover points are generated, but those basically run into the same issues as assertion generation.
Just to add to my pessimism, there’s just not enough good Verilog data. For hardware specifically (and I don’t know what can specifically be done about this), there is just an insane amount of closed-source designs that contain much higher quality code. I’d wager 90% of the Verilog corpus on Github is just college projects (of which yours truly is a contributor). You can get away with this a little bit in software, because open-source is much more of a thing, and there are real-world systems that are open-sourced that can be heavily mined. Within the world of chips, not so much.
Even if this was promising, there’s a question of how much improvement this has over alternatives.
For instance, oftentimes for the problems the papers posed I was asking myself, “Why can’t we just do formal verification”? Formal certainly has a very real criticism of an inability to scale, but over the course of decades the ecosystem has developed to where we can say with incredible certainty that our ALU or register network works, without all the astrology of prompting. Sure, you can say that there’s a higher bar of expertise for a formal verification engineer than a prompt, but verification confidence is a pretty non-negotiable bar. Perhaps that’s an implicit criticism of the benchmark tasks people use– that there’s a large overlap with formal-able tasks– but that’s the only tasks people can get fudged decent results for.
With regards to code/DUT generation, consider the issues that plague various HLS languages like Chisel. If we already have a verification problem with the mountain of data that exists for normal Copilot generated data, how could we ever attempt to gain confidence in AI Verilog? HLS languages provide a huge boost in productivity as well, but people have quickly found that the real bottleneck in getting to market is not just having a design, but the confidence in claimed functionality.
The last comment I want to make is about testplanning. Often for a feature we will discuss and decide what the main claims are from a spec. Someone writes the checks and cover points, and during final testplan review, we sit in a circle and kinda play hotseat. All stakeholders ask if x corner case was considered, where y check exists, how z was stimulated. The testplan will have tables and pictures to explain that because this signal truly represents a branch misprediction, we should have that property covered.
How can this testplanning happen if some LLM generates everything? In order for me to explain why generated_ambiguously_named_signal_V192 represents a branch mispredict, or what this one assertion means, I have to spend time understanding the design anyways, and isn’t the point of this AI to save me the time needing to do that? I don’t consider the physical writing of the code difficult, but the thought to understand it, and the ability to explain it.
In short, trying to use their outputs feels unreliable, not much better than existing tooling, and non-transparent to debug.
That said, I don’t completely think LLMs are complete crap. I actually do think LLMs have some uses, just that it feels like a losing battle to try and hack some trustable flow.
I’ll save the somewhat interesting areas perhaps for a part 2 because this is already quite long, but here’s one interesting thing Google did. There’s some issues translating fuzzing into the hardware world, but the notion of using an LLM as a verification assist instead of a replacement is interesting (i.e. I wouldn’t trust it to write my assertions for me, but perhaps it flags a warning that might be interesting to investigate).