Inventing it is 80% of the fight
The Cost of Nukes
Alex Wellerstein argues that inventing the nuke was hard, but maintaining it was harder. In terms of the technical and social cost over decades, all the old warheads we upgrade, nuclear waste caves we create, and the political capital spent domestically and abroad to ensure our tools of science are used benevolently are immense.
In the 50s, the powers that be foresaw the upheaval of their new reality and thought maybe reckless usage of nukes should be reigned in. Perhaps one huge oversight, as brilliantly storied by Veritasium, was the Partial Nuclear Test Ban Treaty which would ban nuclear testing in the air, water, and space, but not underground. Verification of a full-ban-treaty had been a massive deadlock to passing anything for years, because current tooling to detect an underground nuclear explosion couldn’t distinguish them from seismic activity (for some time, they deliberated using a threshhold 4.75 on the Richter scale as a method of distinguishing, but I wouldn’t want to bank my country’s sanctionability on that).
One haphazard proposal at the time for “underground verification” coverage gap involved having up to 12 annual inspections on every parties’ sovereign land. The Soviets considered this unacceptable as their perceived risk of espionage was too high. Plus, even though the US proposed this enforcement mechanism, the human inspectors were not terribly reliable.
It wasn’t until Kennedy picked it up from Eisenhower and tied it to his success as a president did political traction continue, but the issue of compliance with underground testing remained. Eventually, with pressures mounting ranging from the Cuban Missile Crisis to even more countries (i.e. China and France) acquiring nukes, something had to get done. Kennedy had promised, and it was beginning to look like the US wasn’t committed, so underground verification as a whole was dropped and the treaty passed in 1963. Better to have something than nothing, right? Perfect is just the enemy of good. We can just bootstrap a comprehensive test ban once we get our seismic detectors complete!
This bootstrapping took 33 years, and the Cold War showed no abatement. The verification methodology finally matured enough to make a comprehensive test ban.
Scale, Verification, and Second-Order Effects
Everything is pros and cons, value-adds and value-sucks

Perhaps one of my favorite websites is Retraction Watch, something that is incredibly emblematic of the replication crisis and our human ability to digest information as a whole. As a cynic I like to hear about what went wrong than what’s right. Papers can get picked up by media like wildfire, which maybe later are found to be faulty, at which point it may have already deeply permeated the public consciousness. (I very much remember this article (actual paper here) wildly inflating a Google paper about AI taking over chip design.) The ability to scrutinize, craft methodology, and analyze data is just as if not more crucial than the research itself. The method of obtaining information is just as valuable as the information itself.
And information is plentiful. Our tax laws are so complex we pay billions to companies and indirect auditing costs by the IRS. GPT-X et. al has provided god-like powers to create information, yet we possess minimal checking tools and only those with “true expertise” in the domain can verify it properly. Amazon has hundreds of thousands of products and reviews on those products that overload the consumer with information to confusion. Intel’s Software Development Manual spans 4 volumes for a cumulative 12000 pages and is continually being added (not to pick on Intel; even RISC-V may get bloated someday. That’s arguably the nature of software’s demands of hardware).
It takes time to parse through tax code and gather the last 2-3 years of finances. It takes time to read what ChatGPT spews out and discern its nuances. It takes time to differentiate a review bot or an incredibly simple human. At a certain point, there ends up being so much time spent validating, debating, and cross-referencing an invention or idea that the original gains are moot. Especially in an age of information overload, there is immense value in anything that improves these verification costs.
One massive reason why Google displaced AltaVista was because Google invented novel ways to navigate the surge of information from the web, a problem that plagued AltaVista with spammers and fraud galore. Google didn’t “invent” the search engine; rather, it provided tools to navigate the ocean of data. It instilled trust in its product, and allowed users to not second guess themselves (funny how this good faith is eroding). Early Google saw the money maker with a search engine was not in just providing a vanilla interface to the user and telling them “good luck”, but really in verifying information and arming its users with accessible tools.
Verification often isn’t sexy, but it can be a huge pain point for people, and if haphazardly done, can be so costly to ruin the entire value-add.
Scaling Requires (Equally Scalable) Maintenance
“bro just scale it” is easier said than done. When pursuing an idea to a larger potential, there are often counterforces at play.
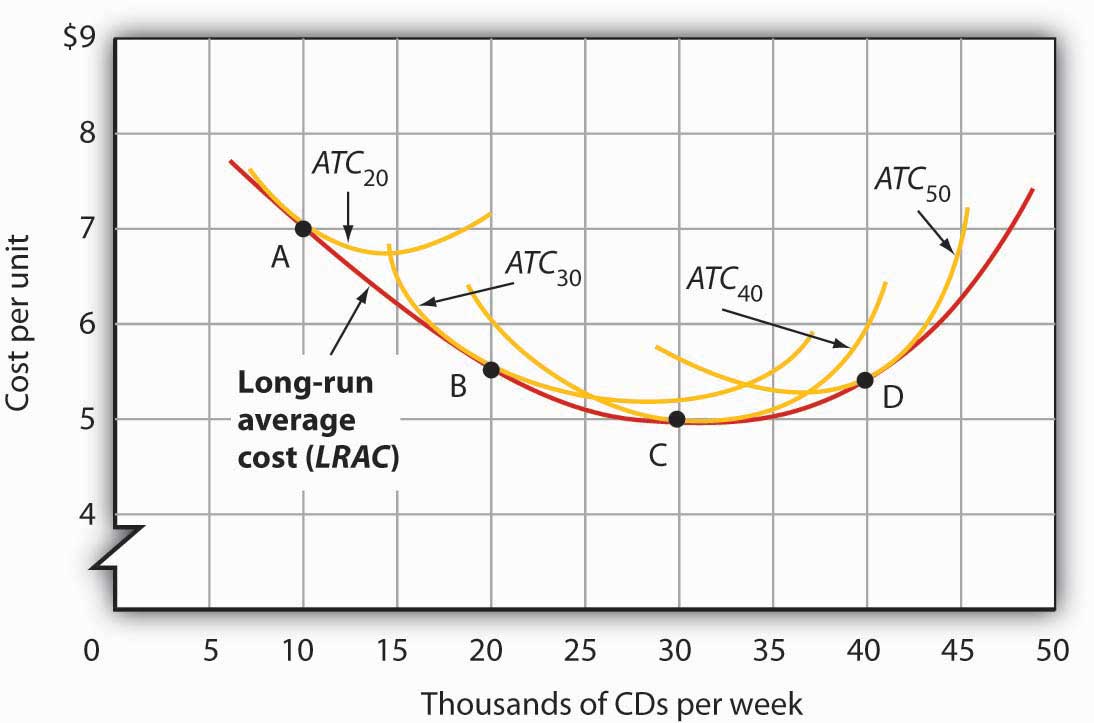
To borrow the idea of LRAC and SRAC curves, one might say every invention creates an SRAC curve down the longer LRAC curve of whatever domain. In scaling an idea, we reach its limits. Gradually, the exploration/usability/validation costs in crafting a new tax law or a new custom Javascript instruction (looking at you FJCVTZS) become too great and necessitate another paradigm shift.
Furthermore, the fight for scale often has to be staged. We often throw the word “scale” around like it’s simple, but much like Civilization, the next paradigm is often unlocked by others. We stand on the shoulders of giants– in academia, medicine, history, society.
Moore’s Law is a great example of an overall larger trend aka journalistic narrative that masks the underlying blood, sweat, and tears driving lithography innovation. The level of scale there is truly awesome, but this is not something that can just be taken for granted and narrated over as “scaling effects”. Every few years, we hit a limit with tooling, from multi-patterning to EUV. These limits represent another SRAC curve to be overcome and require billions of dollars to innovate around.
It could be an enourmous cost that just might sink your ship. Just look at Intel’s 10nm fiasco1. For about a decade, discussions about multi-patterning really became fashionable, partially as a stop-gap for EUV, and partially to eke out extra yield. The core concept is actually pretty simple. We basically laser-etch PCBs at insanely high resolutions, and “multi” comes from basically exposing and etching the same thing multiple times. But there are costs with doing anything multiple times. Doing it twice was low-hanging fruit, but doing it maybe four times (quad-patterning) raised some eyebrows as marginal returns diminished, and there’s speculation that Intel’s 10nm was a dumpster fire for those exact reasons– getting the costs of trying to scale this paradigm under control. One might argue Intel failed to manage these innovation curves.
EUV managed to buy us another decade, but point being– we as consumers only really see the end result, big picture trend of improvement, not the micro-level engineering to develop tooling to keep pushing these boundaries, and so we take the growth of “Moore’s Law” for granted. Without effective tooling and feedback to know when you’re at the limits of scalability of an idea, you could be screwed.
These scaling costs are bubbling up with open-source as well. There’s always such a buzz around open-source, and such a paradigm truly has been a boon to the technology industry, but at a certain point, we’ve created a complex dependency hell and gains in open-source are offset by costs in using it, or security risks. Each additional line of code represents a risk and adds an exponential cost to validate each additional line of code. How many security bugs lay waiting to be discovered in Linux? How long had log4j been sitting out there in an open codebase? What has open-source resolved here?
This is not to lament open-source. It is clearly a step in the right direction as trust and goodwill are critical for security, and I prefer a world with it than without, but often meaningless without verification and manpower. This is partially why the current thrust to aid this effort is in more fuzzing and automation, but often this isn’t a sexy field 2.
I say, we focus so much on creating, we seldom stop to consider the added marginal cost of maintenance. And I’d go further to say that there’s a great deal of money to be made here.
Special Case Study– Buffer Overflows
Three decades after its discovery, the buffer overflow is still one of the most widespread security vulnerabilities. Some rather recent headlines show that this spectre (!!) still haunts us, and half of the vulnerabilities in OpenSSL are buffer overflows from parsing, not from its core competency (airtight crypto!). A whole adversarial cat-and-mouse game has emerged with changing exploitation methods and mitigations around them, but the underlying root cause remains the same– developers make mistakes (or as the NSA politely says, just use Rust idiots).
This is not a new problem. It’s a known known, not necessarily cutting-edge. But it really says something that, over the last decade of CVE reporting, memory issues really haven’t faltered proportionally.
This may be for tons of reasons. Perhaps it really is all just C’s fault. Perhaps it’s security education. Perhaps the pure volume of increasing code is more than what current tooling can handle. Perhaps CVEs are becoming too bean-counter-y and overreported. Perhaps a new paradigm must be invented.
Point being, memory issues are still going strong. Whether it’s a failure to scale mitigations or an unrelenting exponential growth in attacks or even reportability, the state of (firmware) security is not great.
I’ve heard before that there’s often two costs to things. One is the purchase price, and another is the usage price.
A car costs some money, but using and maintaining it might cost just as much, especially an expensive one– oiling it, brake pads, insurance, registration fees, etc. Sometimes there’s even a time cost to fully maximize usage– an owner’s manual, hidden little features, maybe it’s stick and you want to learn stick.
Heck even the skill of driving has costs. Moving locations requires knowledge of the local driving laws; parallel parking is, for many (myself included), a roll of the dice; knowing safe parking areas, for SF especially, to prevent break-ins is a time cost.
Many products simply focus on the purchase price and selling the product, focusing on the bottom line. But consumers decisions are also heavily motivated by the usage price as well; not just financial, but time cost.
Further, in fields where trust is essentially the product backbone– medicine, security, hardware, I’d argue even government– all it takes is one trust-breaking incident to completely turn someone off. A bad pill, a horrible breakin, a broken chip, and a lying government (<insert joke here>); poor reliability magnifies these costs to the consumer even more3
I think we make too much crap without thinking if it’s usable for the normal person, and if you want to scale, you need some better tooling.
-
It’s literally in Intel’s presentations to have 14nm++++. Gotta keep milking it. ↩︎
-
This isn’t really the case in hardware, honestly. Often verification is the bottleneck in chip design, and I think as a result it’s been treated with immense respect and resources, though I have my complaints. ↩︎
-
I’ve unironically stopped using Amazon as much because of all these reviews and fake suspicion brand names. ↩︎