This is the first blurb on a potentially many-part series on what problems I aim to tackle in my career.
Three People
Sean is a CPU architect. His job is to work on the system’s memory hierarchy– store queues, fill buffers, translation caches, etc. Or at least, his job used to be simpler back in the day, before these annoyances.
Now, in code reviews, he’s asked whether he thinks his implemented optimization will cause a side-channel leakage, whatever that means.
“Did anything show up in nightly regressions?”
“No”, he responds, “But that depends on our stimulus. It’s always possible another invariant is here that our stimulus doesn’t cover”.
A circle of nods and grunts. Somebody makes a Jira– “TODO– Think about this harder”.
Mary is a kernel engineer whose expertise is in memory management. Her team has just purchased a hot new ARMv8.5 CPU, previously using a Skylake, and her job is to modify their company’s memory allocator to use the memory tagging extension.
She’s quietly happy about making the switch– after all, ARM CPUs are more secure than Intel CPUs; there have been so many side-channel bugs in Intel CPUs in recent years. These had been especially concerning to her, since the modules she handles directly spans multiple domains of memory, and every time she had to make a patch. Now she won’t have to worry as much about writing potentially vulnerable gadgets.
Still, she wonders, maybe I should just compile with retpoline, just to be safe.
Alex works in product security at Google’s Cloud Platform. His job is to identify and mitigate any vulnerabilities that puts customers’ data at risk, because as a Googler, he cares about making the world a better place :).
He drinks his morning coffee reading about “Spectre in the wild”. Hardware is fascinating– these silicon attacks are super cute tricks.
He finishes his cup and moves on to examine last night’s run of AFL. He sees a crash log with a corrupted kernel pointer. Elated, he dives into the crash, wondering just how malleable this kernel address might be. It’s far more convenient and practical to exploit software bugs than silicon, though part of him wishes he paid more attention during CPU architecture in college.
The Problem
Twenty years ago, software sucked.
Software still sucks, but twenty years ago, software sucked in a very different way. It sucked because people were churning out software like never before– partly because of the dot-com bubble, and partly because it was so easy to LAMP it up. It took decades of standardization, catalogueing, XSS advisories, stack smashers and Bill Gates memos for software to at least become kinda better.
I say kinda because, well, for all the 2000s work in standardization and OWASP classification, the number of CVEs never slowed. It was only thanks to some ridiculously impressive tools to enable verification of these standards that the industry of “software security” really came to fruition.
Twenty years ago, we didn’t even know how much software sucked. At least today, we have some (scary) idea.
Now– Hardware security sucks, and we’re only just starting to figure out how much.
Why is it sucking?
Something something “End of Moore’s Law” blah blah1.
Everything done in software can be done in hardware – and faster. We have come to expect insane 10% YoY performance gains from our products, and thus there is pressure to squeeze out every bit of performance via highly specialized accelerators and custom CPUs to tightly integrate stacks. Controlling the hardware means you can have full coordination with software and constantly iterate various optimizations. For instance, build your CPU like you can build a pizza!
The most obvious cases that a hardware implementation provides a substantial speedup is cryptography. AES, ECC, SHA, RSA, DES, QARMA– every TLA (three letter acronyms) under the sun has been implemented in hardware.
But this has expanded beyond cryptography. Features like control flow attacks, containerization, data storage, execute-only memory and 20 other things that used to be done in software are gradually being punted to hardware.
From a software perspective– this is magnificent. No longer do I have to worry about Spectre attacks/side-channels– I just have to call CSDB (on ARM) and drink my coffee. Even better: just let the compiler do it. Not only that, but I can rest assured it’s more performant than any software solution. (Side-channels are a particularly nefarious case w.r.t hardware vs. software performance. There are some
attempts to claw back some performance though. My overall point stands.)
While I speak about security-specific examples, the principle of abstraction/indirection has truly enabled software to eat the world.
In some sense, indirection and abstraction exists in every field as we push current tools and methodologies to their limit. In physics, we shipped parts across the US to dig deeper at the muon once our conventional tools failed. In neuroscience, we used MRIs and magnets (how do they work?) when lobotomies reached a limit. In semiconductors, hundreds of billions were spent to build the infrastructure as current multi-patterning technology (current at least for Intel’s 14nm++++++++, last-gen for TSMC) were insufficient for shrinking metal pitches even further.
This is very much a good thing. That’s the point of tooling after all– to use it as a stepping stone for advancing human knowledge and increasing productivity.
And here lies the problem challenge, if you’re an optimist. As we punt more and more software features to hardware, what minimal tools we have to support software security become obsolete. Intel SGX for instance might provide certain confidential computing properties– properties that might normally be verified in software security pentesting– but how well do you think Intel actually models, verifies, and validate some of these properties? (Not
amazingly)
The massive complexity of software is bleeding over into hardware– but where the tools for software security are suboptimal (to put it lightly)– the tools for hardware security are non-existant (again, putting it lightly).
There are some efforts to bring traditional security testing to hardware (like fuzzing, symbolic execution, and formal modeling), but it’s a young (exciting!) field (and something I’d hopefully be able to discuss in the next (?) post).
Ignoring security, the decades of infrastructure work put into normal verification is still evolving. Hardware is not patchable, and any fixes in software often come with huge penalties. How easy is it to throw in a “security spec” on top of some of the already most complicated systems on the planet? (Not very).
A Case Study
Let’s look at an example of a hardware security bug and its product lifecycle. While a toy example, it validates my point that the increasing layers of complexity make security fun difficult.
Ariane (now called CVA6) was the chip used in HACK@DAC20, a competition where you are provided a purposefully vulnerable SoC and may hack it however which way. On the SoC are security critical features like a crypto block, a secure JTAG module, a secure ROM– generally barebones security. Accompanied with it is also a very basic kernel to interface with the SoC’s crypto accelerators, bootloader, and MMU.
So, let’s suppose you’ve built this entire software-hardware stack. You want to sell. But how do you check it’s secure2? (see replicated repo/attempts here; I should do a writeup someday).
Suppose there’s a typo in the design where the address space of some system timers spans 1GB.
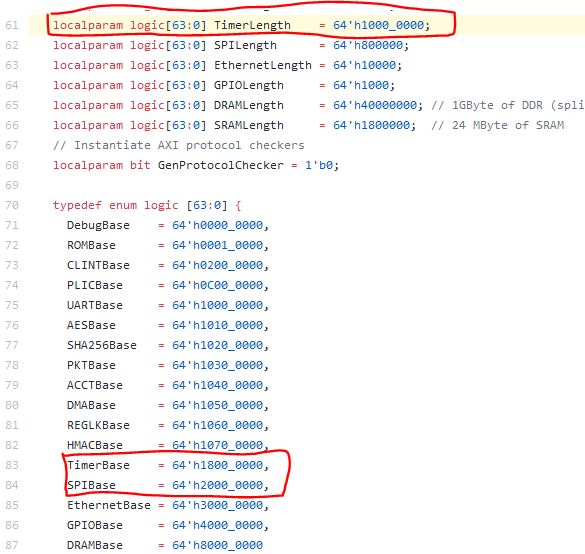
This has an impact on the AXI crossbar, which directly uses these package constants to gatekeep between agents. In this specific case, because of this typo, memory requests between physical addresses 2 and 2.8GB are sent to both the APB timer and the SPI mapping. Depending on how software gatekeeps timer requests, this could lead to arbitrary read/write on whatever is plugged into the SPI interface– which, on many FPGAs, an SD card is used as bootrom3, and usually overwriting bootrom is suboptimal.
Furthermore, as mentioned, from the timers’ perspective, any request to an SPI device may overwrite timers. Many timer controls in the timer module use only 2 bits to address its counters, creating a secondary vulnerability whose exploitability also depends on how software manages timer interrupts and/or configures the RISC-V PLIC.
(The CLINT has its own timer but is managed by the testharness rather than a specific module. I say “depends on software” a lot here).
In any case, this is a multi-layered issue. So how might each of our characters notice and mitigate this issue, and what impact does it have on their work?
-
Sean notices that he made a typo– the length should be 4KB not 1GB! He shakes his head, not sure how his verification team missed such a simple bug. Perhaps there aren’t enough tests done at the full-chip level.
-
Mary is pulling her hair out. As if seemingly randomly, whenever she writes files to her inserted SD card, a timer interrupt occurs– IMPOSSIBLE. She debugs the cycle registers and sees that the registers actually contain the very data she’s writing out!
She sighs; the docs say timers’ address space has a length of 0x1_0000, but apparently not. She reconfigures the IOMMU during firmware initialization to fully isolate the two devices, and pushes to her branch for review. “I hate this new vendor,” she mutters under her breath.
-
Alex is dumping some logs from AFL. He is reading documentation for his team’s brand new server chip and testing some DMA syscalls on the chip’s address map. He sees some interesting memory traffic while rerunning crashes– some addresses accessing the SPI interface are also accessing the timers. He’s not majorly concerned. There isn’t any plan to actually use this address space since they don’t have any external devices using it.
He does have a minor concern that it’s a secondary way to modify timers, but it’s gated by DMA access, which is already a heavily privileged function. Any rogue DMA access would have no need for a secondary backdoor if they could just use the frontdoor.
Still, it’s unquestionably a bug. He files a low severity bug report and passes it back to the firmware team– fix documentation and restrict DMA access controls.
What is the right approach here? The answer depends. What is the impact of the bug? Is it exploitable? How easy is a fix? What is the impact of a fix? What is the root cause? These answers vary at each point in the development lifecycle.
For Sean, the bug is quite severe, but the fix is easy. It’s a no-brainer fix and has no real consequences, especially since the spec/documentation explicitly has this expectation.
For Mary, the bug is also quite severe, and the fix works but is not too desirable, at least relative to Sean. One, it took quite a long time to discover, wasting precious cycles of Mary’s brainpower and literal compute power. Two, these IOMMU controls are still theoretically mutable by other software. Even assuming it’s not an issue this still introduces dependencies that wouldn’t exist had Sean just wrote better code. Software changes, hardware (mostly) does not.
For Alex, the bug is mildly concerning and has limited impact. The affected component doesn’t exist! Furthermore, its exploitability requires an adversary to already be privileged, at which point writeability of arbitrary memory is already possible. If a car crashes, does an unlocked door matter?
The Problem with Hardware Bugs
All in all, the vulnerability was introduced at the silicon level. While it was mitigated by software, it cost quite a bit in [A] developer time (Mary and Alex’s debugging) and [B] product impact (performance, certain functionality, etc). Without a tight vertical product integration process, the later in the design process we are, the harder the fix, the greater the cost.
Part of the reason for this just-in-time/algorithmically lazy approach to security is quite logical– The buck stops here, or rather, with Alex. The only way to really know a product’s security is to fully evaluate it the moment before “releasing into the wild”. After all, Alex concluded that our vulnerability wasn’t as major an issue as initially perceived. This analysis could only be done with this approach.
But this was a reasonable simple case. Here’s a slightly more nuanced vulnerability in our SoC which is essentially ret2spec/specRSB. In a nutshell, the valid bits of the RSB FIFO aren’t actually used to qualify any fetch address before getting queued up. Whoops!
Or take even this one that was literally released as I write this post. Turns out all our assumptions of the backend being utilized as a side-channel are wrong, which doesn’t surprise me.
Again, while it was fixed in software (well, really three fixes), the performance impact is not negligible– the real solution should be to fix it in hardware, and there are some interesting things one can do (this and this are my favorite proposals).
Furthermore, there is a difference between something being vulnerable and something being exploitable. Vulnerabilities, for all the fanfare they may get, are still in some sense theoretical. They are undoubtedly leaks in a system, but exploits are what happens when you actually run water through it. This goes back to our just-in-time approach to security– it takes someone like Alex who posseses omniscient knowledge over how exploitable a vulnerability might be. As long as Alex does his job, we will have zero concern!
:)
And then there are cases where vulnerabilities that might not be a “leak” at the time can be chained together to increase their impact. This is a technique that leverages speculative side channels in black-box environments to bypass the mitigations: 1) array index masking and 2) randomization and various gadget-hunting defenses like ASLR and execute-only/XoM.
Security Across the Development Lifecycle
The takeaway– Hardware is undergoing a massive paradigm shift as the boundaries between hardware and software soften. While security is obviously necessary for specific parts (enclaves, encryption engines), this is largely done at the block level. Recent events have shown a holistic approach must be done across both hardware and software for components. New methodologies and toolchains are required as the security properties of our products are getting harder to validate in software.
This holistic approach can be represented in a neat diagram known as the “Hardware Security Development Lifecycle” below (thanks Tortuga)4. I am not a Tortuga shill, it’s just a nice diagram.

Our above examples can be broken down in this lifecycle as well. The bug was introduced during “subsystem design” by Sean, but lack of any dedicated security verification in RTL resulted in further downstream affects in “Low-level testing” (cue Mary pulling her hair out). Furthermore, lack of any continuous security verification and cohesive communication resulted in wasted engineering time, had Alex stepped in to mention the hardware requirements (either Post-Si Testing or even threat modeling).
Of course, not everybody can be Apple and have every engineering team under the same roof.
The IP Security Assurance Standard aims to address this partially from a third-party vendor perspective, e.g. if you purchase hardware, the vendor provides further documentation/reports on security risks for the hardware, theoretically enabling vendors to do better risk management.
The problem– these methodologies and toolchains are currently not very great. The IPSA Standard is a start, but has its own problems which most certainly necessitate its own blog post. Namely, that additional documentation is not the enabler of progress– see the multi-volume 9000 pages of Intel’s Developer Manuals– rather, it is the centuries of engineering time invested in building a massive ecosystem of tools and frameworks.
Going back to our above diagram (again, thanks Tortuga)– the biggest problem in hardware security is not the threat modelling/security spec work of IPSA, or post-silicon security efforts like Google’s Safeside. It is the abysmal state of everything in between.
Which it appears Tortuga’s products can already solve if you purchase Tortuga Radix Solution™️ (Seriously, I promise I’m not a Tortuga shill, they’re just one of the few companies who have noticed the same problem I have and I guess started their own company to address this market before me)
Examples
Half-Double: Rowhammer
If you’re not quite convinced of a need for tooling to aid security verification, let me draw your attention to a new Rowhammer technique that was literally released the same day I finished my first draft and caused me to rewrite most of this post. Thanks Google.
From the blog–
This is likely an indication that the electrical coupling responsible for Rowhammer is a property of distance, effectively becoming stronger and longer-ranged as cell geometries shrink down
From the paper (bottom of page 13)–
… we saw mappings from 1 that we used for this work. This suggests that the published findings about distance >1 Rowhammer are simply a result of not taking the correct mapping into account. Given that the patterns we found appear to be distance 2 attacks, our industry partners were skeptical about them.
It’s interesting that both the researchers and “industry partners” had this slip under their nose.
Part of it might be, as Google claims, shrinking cell sizes. Whereas previous > distance 1 attacks were purely hypothetical, or at least too noisy, as even the researchers from 1 note that double-sided was far more reliable, times have apparently changed since 2018, which itself is an interesting hypothesis.
The other part is the “industry partners” have crappy security verification suites.
Rowhammer was (and still is) pretty groundbreaking stuff. Target row refreshing (TRR) for all its faults still provided some mitigation, and is still generally accepted as being “decent” assuming a proper implementation. But, as Google notes, for many vendors, it is only suffice against distance-1 attacks.
However, if you actually read the paper (and not just the abstract, c’mon guys) in section 6.3, and as Google notes, there’s some definite discussion that these bitflips still occur beyond a single victim row, which is why I’m quite surprised (or I guess, not surprised) that the “industry partners were skeptical about [distance-2 attacks]”.
Put on your verification hat for a second and transport yourself back to 2014. You read that bitflips happen in multiple cells, not just ones 1-row array from the targeted cell. You are told that TRR is implemented and is a totally complete mitigation against Rowhammer. How do you verify this claim?
Apparently, I just check that the next row over has no bit flips and call it a day. Ship it! Mitigation complete! High five.
¯\(ツ)/¯
Yes, I realize > distance 1 was hypothetical. Yes, I realize that TRR is costly, and chasing down hypotheticals out of security paranoia will just destroy your chip. Yes, I realize it might not be realistic to expect manufacturers to be updated on the latest security research such as decoy rows or weighted aggressors (though I still wish they would, however unrealistic).
But– I’m not saying to have utilized TRR to its most extreme and refresh all of DIMM– I’m saying that a proper security verification environment should have at minimum detected distance-N attacks. It’s not difficult to model a double-sided aggressor with varying strides to the victim. All it takes is putting it in a for-loop.
One point feel is worth repeating though– it’s fascinating the VUSec researchers missed this initially. I don’t think it’s “a result of not taking the correct mapping into account”, though that is a simpler answer. The varying hardware between 2018 DIMMs VUSec used and 2021 DIMMs Google used is also reasonable, and the implication that larger distances have suddenly become more practical due to shrinking sizes is interesting. Kinda like with crypto, what’s old may become new again.
Consider how this vulnerability fits into our security development lifecycle. Most certainly, there was some threat modeling and security planning done for this, but as I mentioned above, I believe that’s where the lifecycle was cut short. Any and all verification of this security mitigation was purely punted to post-silicon verification, i.e. traditional security pentesting.
And I understand why. It’s hard to define “leak” in a simulation. It’s hard to create a testbench model for a realistic attacker. It’s hard to create stimulus that gets good coverage (e.g. distance-N attacks) without overconstraining yourself. But these are lazy excuses.
Consider if this same approach were done towards normal functional verification. “It’s too hard to create random stimulus for MOESIF in our simulations, so let’s just have the software team find ‘realistic’ bugs.”
We (almost) never accept “it’s too hard” when verifying ridiculously complex CPU features, so why is it okay for security features?
I See Dead uops: Leaking Secrets via Micro-Op Caches
This paper is partially what inspired this blog post.
Minor Background/Ramblings
Before discussing the paper, I want to bring up Speculative Taint Tracking from my old research lab. In short, STT proposes an architecture that is basically DIFT (dynamic information flow tracking) but in hardware, where a source of “taint” is the point an instruction speculates, and the bound or “untaint” occurs when that instruction completes.
(Aside– the problem of hardware DIFT is very similar to clock trees during physical design. Lots of implementations of hardware DIFT have failed in the past, largely because 1) the performance cost of taint quickly pollutes every dependent data instruction and 2) the area cost quickly explodes as data has to be tagged and tracked throughout memory hierarchies. STT gets around this problem by essentially hijacking register renaming to track taint instead. Fun read!)
One of the novelties of the STT paper is the idea of speculative sources and speculative sinks (also referred to as side-channels and covert channels)– for example, Spec v1 used the PHT as a source for how faulty data is read/computed, and the data cache as a sink for encoding the faulty data.
Phrased another way– STT essentially posits that the exhaustive list of speculative attacks can be phrased as being a cross product of {the set of sources} X {the set of sinks}, whatever these may be.
Here is an up-to-date (as of early 2021) list of every speculative attack. It aims to classify every current attack, as well as propose potential attack vectors as well.
Combine this classification with STT’s information flow model of sources and sinks, and we notice a pattern– Just about every attack on that list uses the backend of the CPU as a speculative sink (i.e. executed an instruction whose source operand was speculative, and did timing analysis based on the speculatively executed data)
Meltdown used the TLB as a source (since the CPU handled exceptions late), and L1D as a sink. Spec v2 used the BTB as a source and L1D as a sink. Fallout used the memory disambiguator as a source, and L1D as a sink. Zombieload used the Fill-Buffer as a source, and L1D as a sink.
There are a couple attacks (e.g. SmotherSpectre) that are slightly different in that they leverage functional units as a sink/encode faulty data instead of the L1D, but these still fall under the “backend” of the CPU.
In other words, this list of attacks provides a lower bound for the number of elements in each set and shows that there is an N-1 mapping of sources-sinks–
{TLB, BTB, Fill-Buff, StoreQ, ...} X {L1D, FU,...}
// Structures containing data (source) Structures used to encode data (sink)
Who knows what other elements might reside in these sets? Who knows! Well, we can get a decent idea by just staring at our design, but oftentimes designs are just so complex that’s not too feasible (also side-channels are just so not well understood among architects it’s not reliable).
What I do know is that generally, many attempts for mitigation tackle this problem by preventing sinks from being utilized– this is reasonable, since STT posits that these attacks rely on both sets after all.
But what happens if you take these at face value? Which leads us to…
Actual Paper Discussion
Suppose we steal these code snippets off Github and run it on our design. Doing so would certainly protect against all known attacks, but we should really be a bit more diligent in expanding these sets, right? After all, fixing hardware is costly.
Let’s put on our verification hats. What are some things we can do to potentially discover these new attacks?
The biggest hurdle when it comes to discovering attacks is not the searching aspect. It is the detection and classification of these cover points that are the hardest part. It requires a further classification and checker/monitor/insert verif term here on top of existing infrastructure.
Just about all of these attacks are cover points you’d hit with proper stimulus anyways. Meltdown– pointer chasing loads across exceptions is a cover point. Spectre v4– forcing mispredictions on the memory disambiguator should already be done; and when the source data comes from multiple uArch structures, you get the MDS variants. This newer paper? I’m positive “speculative issue of micro-ops” was a cover point. Billions of CPU years are spent running simulated software on hardware designs, and thus it is incredibly likely that this edge case was thought about in pre-silicon.
Thus, the “secret sauce” to escalating a basic cover point into a security vulnerability is not the creation of proper stimulus, but rather, the ability to detect and check against our desired security properties (jargon wise– a checker, a scoreboard, a golden model). Thus, when creating proper security testbenches, we should consider the failure mode rather than the constrainability of stimulus, because the stimulus is typically already necessary for functional completeness.
Back to the paper– to use the model of sources –> sinks, we see that the utilized source is Spectre-like, but the sink is the uOp cache. Viewed another way, this is just a speculative variant of a long-ago I-cache attack. Fundamentally, this is a virtually indexed uArch structure, and thus is no different from a typical L1D.
Going back to our idealistic mapping of known attacks, I believe if you were to consider the uOp cache as a possible sink (as you should, given its data dependency) and had a proper monitor checking these signals, this would have been caught.
Of course, this is idealistic. Perhaps it’s difficult to scale a monitor infrastructure and just “including a new mapping” and pulling out all the relevant signals is hard. Perhaps it was just an oversight in including this sink element. Perhaps an error in modeling “leakage” occurred. There are many reasons why it might have slipped by. But overall, I still believe this fits into my model– all that’s next is the execution.
Next post will be some cool early work in what I view to be the next step in the industry’s pursuit to relentlessly copy uh, learn from the past work done by the software industry.
Part 2: Fuzzing
-
I hate this phrase, because it’s more symptomatic of being at the top of the S-curve than any “real” thing, and a trend that’s been observed/called out across literally every other industry has a “___’s Law” that a huge wikipedia list documents all “Laws”. It’s not a unique thing to hardware, and not the whole doom and gloom that such a phrase paints. ↩︎
-
Theoretically, you would state your threat model to your customer and provide documentation of your efforts. In practice, you just throw some pictures of locks in a blue backlight and pray you’re not asked for details. ↩︎
-
Note that the exact testharness used doesn’t generate the SPI slave. So while slightly disingenuous, it’s enough to get my point across, and I’d argue that you’re not providing the testharness– you’re providing the core/SoC, and this ‘InclSPI’ paramter isn’t always going to be tied to 0. [unless you have insanely tight vertical stack control i.e. Apple]) ↩︎
-
Of course, there’s also the Software security lifecycle but because it’s hardware, it’s gotta be newer and shinier. ↩︎
{kind=link}