10/3 EDIT 0: This is the first draft, and honestly I have a problem with writing drafts too much and polishing too much. But given this is more of a survey and my intent is to be a bit more piecemeal, I am just decided to call it here and add more as I continue. I am very fine with it being an incomplete list, and it will necessarily have to be filled in.
At this point, there are so many CPU vulnerabilities out there and I’ve had so many discussions on the nuances of them I need some reference manual. The general intended audience of this is hardware engineers, perhaps people like myself who aim to understand these at the hardware level. This assumes you have some background on side-channels.
Minor Background Refresher – Meltdown Explainer
Most of material here is gathered from Chris Fletcher’s lectures, this survey, and a pretty great presentation from Moghimi’s Medusa slides on how he discovered it. A pretty old classification and analysis by many of the first discoverers of Spectre et. al still apply (in nice little web form here as well). To me, the fact that it’s so old (is 4 years old?) and still in some sense predicting these attacks is quite interesting.
Anyways, generally speaking, many (maybe all?) of these attacks can be said to have 2 primary gadgets– First is the actual leak, and second is the exfiltration of that leak 1. The other phases involve what I call “massaging”, steps you might take to first setup a known state, make an attack easier, or de-noise exfiltrated data. These steps might involve clearing the cache, fiddling with branch predictors to make a large speculation window (one might also say “huge mispredict
penalty”), or even just rerunning the gadget you’ve made in a loop.
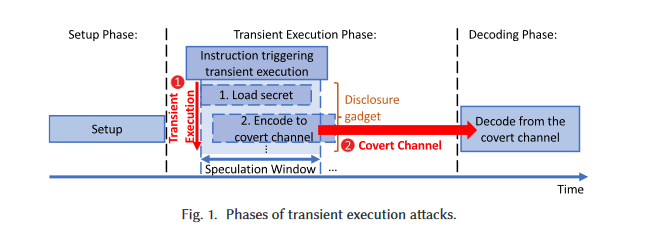
Consider how Meltdown factors into this model (again, slides copied from these amazing slides). For the astute out there, if you’d really like, you can follow along the exact “phases”, down to the exact gadget, since everything is rather self contained in this file. To me, Meltdown is a really great branching point for an explainer, cuz it’s (scarily) simple.
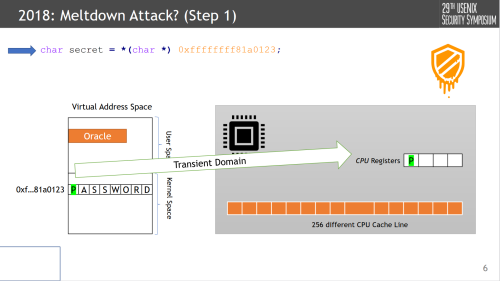
In this slide let’s presume that the address 0xff...123 is some kernel address pointing to our “password”, and our snippet is executed as a guest. THIS RIGHT HERE is, in some sense, where the vulnerability in many CPUS laid (still lie?). Architecturally, this invokes a permission exception, but speculatively, this exception is only really handled at retire time (using the 5-stage pipeline model of F-D-E-M-W). At least, this was the logic of many designers, the logic being who cares when an exception is presented, so long as it happens eventually.
Anyways. Continuing on, under this assumption, nothing stops the load secret = *[0xff...123] from going out and the data returning “P” for it to be used around.

This second instruction is executed with a dependency on secret. One might imagine this dependency getting bypassed via a Mem->Ex pathway, and that in the next cycle, despite the older instruction being retired/“seen” to be illegal, still gets issued through the cache and allocated.
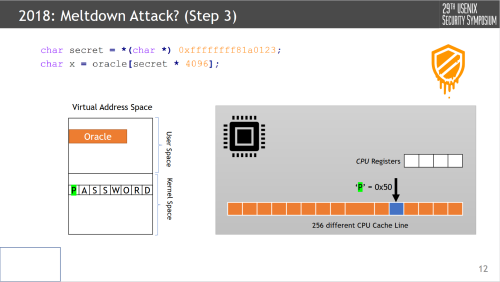
Steps 1 and 2 above may be considered the “transient execution” phase. But step 3, decoding the leak, is quite critical as well. Two key components to make this work are the secret * 4096 blurb and the oracle of 256 different cache lines. In this attack, our goal is to decode ASCII text, and to do so we need 256 “fresh” cache lines (given that’s the keyspace). Further, cache lines on many modern CPUs are 4k-page aligned to get a unique tag, so to uniquely identify ASCII text utilizing a
cache we need 256*4k bytes, which is precisely what they do here (though to be quite honest idk where 300 comes from, wiggle room is always nice I suppose).
All together, because we’ve setup our cache lines in our oracle, and we know from steps 1 and 2 that some line (specifically P = 0x50) has been accessed, we can just do a Flush-Reload sweep over our oracle to determine it.
This sequence, by the way, may often be referred to as a “universal load gadget”, or a “load-op-load” sequencing. Breaking the raw C down into assembly, it essentially looks like
// This essentially is the raw gadget used in all attacks.
// There are many parameters that can be played with.
// the number of ops between i1, i2, i3; the type of load you use; the initial memory state;
// whether or not the gadget is speculative, and under what type of speculation; etc.
i1: ld x1, [mem]
i2: mul x1, x1, 4096 // whatever generic op to help encode; in this case, for 4k aligned cache
i3: ld x2, [x1] // encode value into cache
Obviously all of these steps are quite intensive and deeply linked. Each leak requires deep knowledge of the hardware, and each “decoding step” is rather bespoke, though all out there so far involve the cache. There’s tons of as I called “massaging” to setup and decoding stages, such as making the leak bigger to exploit easier or screwing with the prefetcher to reduce pollution in the attackers state. There’s tons of “fluff” and research going into making these “transient windows” larger.
Most literature is starting to differentiate the “leak” actually happening, and then it being observable. Some call it accessors and transmitters, sources and sinks, etc. They all refer to the same general idea of there being 2 high-level requirements for these attacks to be possible.
Overall, it’s a fascinating world of CPU attacks.
What follows is a brief Systemization of Knowledge (mostly for my own personal benefit), with no particular order to the timing of these bugs.
General Taxonomy
At https://transient.fail (paper here) there is essentially a list of every transient attack found up until 2021. Despite this age, the general classification of attacks into a “Spectre” bucket and a “Meltdown” bucket has been widely agreed upon in the literature. That is, every attack discovered so far is a result of a direct misprediction (Spectre-Like) or an exception or, to a further extent, various “micro-code assists”, i.e. instructions that aren’t hard-exceptions such as line-crossing loads or way predictors (see Take-A-Way) can still cause timing variations.
Of course, there’s actually a bit of a third category that hasn’t been fully categorized. For example, Augury utilizes a prefetcher, but isn’t all of speculation as a concept in some way a prefetcher too? So is prefetching speculation? I’m not sure. But there’s many gray categorizations that I’ll list those out under Misc. as we go.
From a defender’s perspective, it may be useful to categorize things in terms of mitigatability. For example, disabling hyperthreading basically eliminates a huge headache, from TLBleed to SmotherSpectre to certain Foreshadow cases. One other angle of mitigation strategy is to tackle the gadgets comprising these attacks.
I do find that perspective quite useful, but to be honest, I need to figure out how to make my tables better to fit that information in, so lmk if you’re a markdown expert please.
Spectre-Like
As mentioned above, Spectre-like refers to an attack that has some direct prediction element, and a “training” component. Much of the frontend of the CPU (BTBs, PHTs, return stacks, etc) have this element, but things like Spec v4 also exploit the memory address predictor of a CPU’s backend. Most of these attacks have an “oracle setup” be similar to each other, but simply vary in the source of speculation.
It’s difficult to define precisely what a “prediction” is. Obviously, a branch predictor is a predictor, but is value prediction (as is somewhat the case of Inception) necessarily “predictor” based? It’s difficult to tell without being on the “inside” of a chipmaker, but the line can sometimes be blurry between what is a “microcode assist” and what is a “misprediction”.
Spec v1
for (x = 0; x<100; x++){
if (x < array_size){
junk &= array2[array1[x] * 4096]
}
}
| Summary | Mitigation | Impact |
|---|---|---|
| The directional branch predictor (CBT, PHT, whatever) can be trained to misspeculate down a bad path, in this case one that executes out of bounds array elements. | Honestly no great mitigations. The most common recommended one from vendors e.g. ARM is to use some software barrier. Depending on the workload, this may often come at a larger cost. | In my opinion, only moderately impactful. Memory leakage is restricted to a process’s permissions and VA, which is bad for e.g. multiple tenants or kernel process. Compared to Meltdown, it’s not as bad as complete unprivileged memory dump. |
Further notes/comments
In this case, suppose that the if mispredicts taken, and that x or the loop condition is within an attacker’s control. This causes the array1 lookup to occur with an out of bounds index and allocate an entry into array2.
One may optimize this (increase odds of misprediction, make the leakage window longer, etc.) by bit-hacking the loops as the original PoC does; maybe ensuring array_size is evicted from cache too.
Spec v2
for(i=0; i<100; i++)
jmp *addr1
...
jmp *addr2
| Summary | Mitigation | Impact |
|---|---|---|
| The branch target buffer (maybe also known as Branch History Buffer) contains mappings of Branch VA –> target. Often, not every bit of a VA is used to match for a target, so inevitably some aliasing occurs. | Within software the most common one to come out was retpoline, some hardware mitigations include Intel’s IBRS, but still those are a bit incomplete (see notes) | A good bit worse than v1. Compared to v1, where you had to naturally find an exposed gadget, here, you can craft a gadget yourself and point the BTB to it instead. |
Further notes/comments
Intel’s initial IBRS mitigations were mildly incomplete. While there’s no official documentation of how IBRS worked, we can get a general idea of the industry’s ideas by looking at Exonys’s microarchitecture. Ultimately, the authors note that the inital reason the mitigations were incomplete was because there were a fair amount of hash collisions on Intel’s CPUs, deterministically, so once they reverse engineered it, it was straightforward to bypass. That’s why testing is important!
By the way, AMD apparently didn’t have this problem, lol
Overall, Spec v2 is also quite nefarious. With all of the recommended mitigations, some workloads see a 25% perf drop, which is just about unacceptable.
SpecRSB
https://www.usenix.org/system/files/conference/woot18/woot18-paper-koruyeh.pdf
SpecRSB is a small but distinct variant of Spec v2. The BTB and RSB are usually complementary, with the RSB storing a return address as soon as a call is seen (call-return structures are pretty recursive after all, so a stack is a great usecase for them), compared to Spec v2 which largely exploits solely jumps (indirect or direct). In other words, our source of speculation can be the RSB, instead of the BTB. We can trigger the misspeculation simply by writing to it from software, causing the uArch state of a return address be different than its architectural state.
Consider the snippet (basically stolen from the paper above)
func2() {
push %rbp
mov %rsp, %rbp
pop %rdi // 1) pops func2 ptr
pop %rdi // 2) pops func2 ret addr
pop %rdi // 3) pops func1 frame ptr
ret // <-- contains func1 address
}
func1() {
func2();
secret = *secret_ptr; // speculatively returns here, since top of RSB still contains this
junk = oracle_arr[secret];
}
main() {
func1();
}
This example is a little contrived, but the point is to show how a mismatch between architectural and top of the hardware RSB stack can occur. If one were a naive hardware designer, and only applied a patch to Spec v2 (a BTB defense), this displays another way someone may leak data using almost the same instruction components.
Spec v4
array[idx] = secret_val
...
// Suppose branch takes a long time to resolve...
if(<bleh>)
idx = 0xbeefcake
array[idx] = 0 // ...thus has a sorta dependency on the branch
val1 = array[x] // x may be attacker controlled, and CPU speculates that x != idx
// permitting the load to possibly issue first ahead of the store
junk = oracle_arr[val] // loading to oracle landing pad for flush+reload analysis
| Summary | Mitigation | Impact |
|---|---|---|
| Sometimes the CPU may speculate the addresses between two accesses are not the same. In these cases, the younger instruction may execute with stale data. | Public details on mitigations are pretty sparse. One may certainly throw in a fence during uOp assists as many of Intel’s fixes seem to have. I can certainly imagine a couple hardware fixes, but I probably won’t say :) | I don’t think this is bad as e.g. spec V1. It’s similar to spec v1 in that vulnerable gadgets have to exist, but is highly variable on how aggressive the hardware is with speculation, and also due to memory prediction being so much more multifactoral than, say, a conditional predictor. |
Further notes/comments
This is basically an exploit on memory dependence prediction. If we assume that the older store and the younger load don’t have a dependency, we can execute them both in parallel. This, fun fact, is basically why oftentimes the C++ restrict keyword can net some performance gains.
Speaking of performance, what mitigations initially put out weren’t too catastrophic, according to the article, around 1-3%, which I might argue is nearly noise.
There are dozens of variables that factor into this prediction. Only those internal to companies know for sure, but this is basically what the entire MDS-branch of attacks exploits, to varying degress of success, with some very incredible reverse engineering.
Phantom and Inception
Phantom and Inception (in my opinion, Phantom goes into better detail about the root cause, and Inception is more about exploiting it further).
AMD may also call this Branch Type Confusion.
| Summary | Mitigation | Impact |
|---|---|---|
Aliases exist in the BTB similar to Spec v2, but this time aliasing is in some sense coming from a uOp cache. The uOp cache enables a decode misspeculation of a branch existing, which can result in, say, a add instruction still causing a resteer via the BTB. |
Ultimately one needs to “close the window” between uOp cache correction and BTB target prediction and thus varies based on the degree of speculation. Retpoline does still fix this because it basically “floods” the pipeline with RETs. Hardware wise, the only really existing mitigation is flushing, which isn’t great. | See notes |
Further notes/comments
The first key observation the authors make is that speculation can be observable earlier on in the pipeline. After all, a branch mispredict is typically fully detected during Execute, so the authors hypothesize 1) they can control which instructions are fetched 2) these instructions can still leave observable effects during Fetch and Decode, before a mispredict is detected; more specifically, they can still train the BTB with misspeculated uOp cache data before a mispredict flush.
These two theories are highly uArch dependent, but still, at least on various AMD CPUs, this is proven to be done. Much like in Spec v2, where just the branch target is corrupted, these attacks show the usage of the BTB itself can be corrupted (i.e. the indexing is more like func(VA)->target, and if you find collisions on func(VA) for some VA you can also forge a target).
Their super basic example is as follows:
if(x){
temp(); // actual addr of temp is attacker controlled
}
That’s it! There is as I said a good amount more training necessary (see Fig 5. of the first Phantom paper) but a worthwhile cost to still maintain arbitrary (speculative) code execution from an attacker’s perspective.
The two critical steps, uOp misspeculation and BTB training, happen here and here, where they use self-modifying code to “make” misspeculation happen easier.
Another comment on mitigation– disabling SMT (as with many attacks) heavily reduces but not eliminates attacks at least. That’s mostly because SMT can often provide super fine-grained “catching” of windows, given how tightly knit it is for running on the same core.
Impact
I find the impact to be worse than Spec v2; though given we still have some existing mitigations it’s not sky-is-falling level impact as when Spec v2 first came out. The attack is a bit more complex, needing more training and extra reverse engineering, but given that this can still be done “offline” and in an environment where code can be run anyways only adds to the scope of an attack from a victim’s perspective.
This attack also functionally breaks up the need for a contiguous “bad” gadget in the victim’s codebase. The “universal read gadget” often has loads off fluff in between two dependent loads, but this only served to reduce a speculative window size. By adding uOp speculation into the mix, assuming a proper BTB engineering, one could simply directly “jump” to completely disjoint loads.
Zenbleed
https://lock.cmpxchg8b.com/zenbleed.html
Straight Line Speculation
https://grsecurity.net/amd_branch_mispredictor_part_2_where_no_cpu_has_gone_before
Meltdown-like
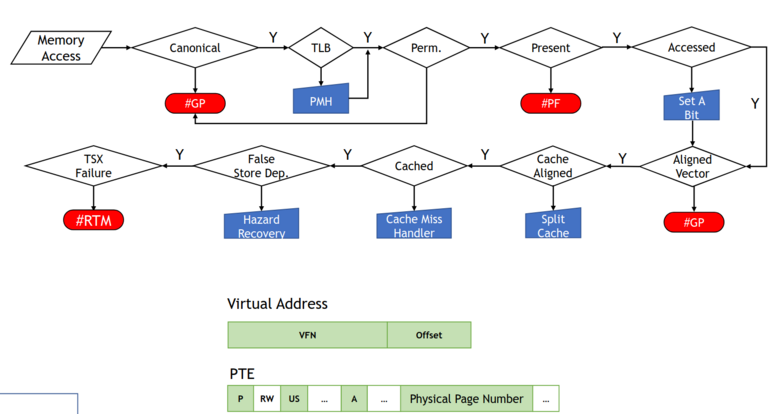
As explained above, Meltdown-like essentially means anything with “microcode assists”. Above is a graph (again stolen from these slides) that demonstrate a little of what I mean.
Essentially every single branch from the “main path” has been shown to be a Meltdown-like vulnerability. Not every one of these is necessarily an exception, resulting in a handful of these cases slipping through the traditional Meltdown mitigation (that is, handling exceptions precisely in the CPU rather than letting it go until retirement).
Spec v3 (aka Meltdown)
Further Notes/Comments
I just kinda explained it in the background but yeah hope it was sufficient.
A further variant known is Rogue System Register Read or Variant 3a basically replaces the first instruction mentioned in the background with a register read instead. Impact is not great, but not as bad as arbitrary memory dumping.
The primarily accepted mitigation for this has been to simply handle the exception precisely– that is, instead of letting a permission fault be handled at retirement, the pipeline flush and steering towards whatever exception handler should occur immediately.
As shown in other attacks though, this mitigation can be insufficient, as not every behavior results in a direct PC redirection.
Foreshadow/L1TF
// This is super similar to Meltdown, except instead of a permission bit exception,
// we have a "not present" page fault. One may simply invoke
mprotect( secret_addr & ~0xfff, 0x1000, PROT_NONE )
// to clear the "present" bit. This can happen either directly or "naturally" e.g. OS swapping pages.
...
char secret = secret_addr[idx]
int junk = oracle_arr[secret]
| Summary | Mitigation | Impact |
|---|---|---|
| Similar to Meltdown, except instead of executing instructions under a Permission Fault’s shadow, it’s done under a Not Present Fault. The data is still fetched in some capacity because a decision has to be made about other fault priority. | A direct hardware mitigation may be tough– again, how do you know (short of stalling the whole pipeline) whether or not it’s permissible without the page’s metadata– but there have been several proposed software mitigations (see Notes). | A bit more nefarious to stamp out, and needs some intervention from software, which definitely affects the efficacy of any mitigation. One may argue it’s a bit more drastic than Meltdown because the Present bit isn’t as “locked down” per se, which I would agree with. |
Further Notes/Comments
https://foreshadowattack.eu/foreshadow.pdf - features the base PoC and background. Initially largely limited to enclave cases
https://foreshadowattack.eu/foreshadow-NG.pdf - expands the base PoC and the attack’s capabilities by demonstrating other methods of clearing the Present bit.
Mitigations in software might include disabling hyperthreading and clearing the L1D directly within microcode on privilege boundary switches; after all, why hold stale data in the cache at all if going from VMM->Guest.
One interesting mitigation proposed in the paper is to have the OS write “not present” pages with a non-canonical address e.g. fill MSBs of the page data with 0xdeadbeef or something. From the state machine above, there is essentially stronger handling and a more direct exception on badly-formed addresses, so it more or less fallsback to a typical Meltdown mitigation.
MDS Attacks
These attacks are a suite of attacks (see also here) that essentially exploit the whole “memory prediction” thing in its entirety. The memory hierarchy in modern CPUs often has caches all the way down and dozens of areas for performance optimizations (read: potential timing leaks). The MDS attacks were essentially the first voyage into this and are also quite a fascinating rabbit hole to go down, given that the secret optimizations around memory hierarchies in general tend to be tightly guarded (and patented). The reverse engineering these researchers had to do was quite impressive.
At the design level, in my opinion, these attacks really aren’t terribly complex. What’s disappointing is the huge similarity with Spec v4 and the failure of those similar mitigations to address them. In some sense, I understand the directed approach to handle these bugs. I also understand that these were mostly discovered in late 2019, when industry was still getting some general grasp on these attacks and various methodologies weren’t fully fleshed out.
RIDL
Rogue in-flight Data Load (RIDL), raw gadget/instruction wise, looks exactly like Meltdown. However, as with many of these attacks, it’s about how you setup the initial speculation and circumstances. Arguably because this essentially is Meltdown, and arguably a bit worse given the lack of needing to “warm up” addresses.
// Pls forgive me for fake mixed asm and isa usage
// Again, tsx is only really used as a fault suppression mechanism
void tsx_leak_read_normal(leak, reload_buf){
xbegin
ld x1, [leak] // addr here is irrelevant!
ld x2, [buf + x1]
xend
}
// Attacker Proc // Victim Proc
for (size_t i = 0; i < ITERS; ++i) { while(1){
flush(reloadbuffer); ld x1, [addr];
mfence; mfence;
tsx_leak_read_normal(NULL, reloadbuffer); }
reload(reloadbuffer, results);
}
| Summary | Mitigation | Impact |
|---|---|---|
| The Line-Fill Buffer (maybe sometimes called a Miss-Status Holding Register, or Miss-Buffer) usually contains loads’ return data from an L1D’s perspective. While these may be drained over time, if executed simultaneously/near in time as a vulnerable gadget, the data can still exist in the buffer and be utilized by faulting loads (see notes) | The first mitigation was VERW. Rather expensive, this instruction flushes the LFB and the L1D by extension on every context/thread switch. Hardware wise, it’s hard to say for sure, especially since other vendors didn’t have this problem (See notes v2) | Intel gave it a bit worse of a CVSS score than Meltdown, which I’d agree with. The lack of address isolation is quite bad, ameliorated slightly by the need for time based contention. |
Further notes/comments
This was an insanely good explainer and makes you roll your eyes at Intel.
To elaborate on the summary and potentially why/how this bug can even exist (keyword potentially, again given the lack of public docs on this), look at the actual snippet. This is wrapped in TSX mostly to act as an exception suppression mechanism, but this could just as easily just be wrapped in a misspeculated branch.
Additionally, one key component of the vulnerability can be seen in Figures 4 and 5. It’s rather fishy that, for the most part, a cache flush is more or less necessary for the leak to occur. This is indicative of the Fill Buffers being thrashed, as every sequential load would then allocate a buffer entry and almost immediately be cleared.
Meanwhile, the victim thread is spinning on a load, also while executing an MFENCE, indicating that, from the victim’s POV, there is at most only ONE single buffer entry at any time on the logical core being allocated. As Figure 3 showed, this contention between the attacker and victim over this single entry definitely leaks data.
Figure 6 is also a compelling case. They show that the value leaked by the victim is rather deterministic. That is, the more a victim writes data to the Fill Buffer, the more likely the value is leaked. For instance, this “1:4 ratio” they reference leaks the data according to the same ratio (20% and 80%); if this were random and noisy, it’d be a rather unreliable vector to conduct an attack.
MAJOR SPECULATION HERE
From this info, we can sorta speculate (lol) on a specific root cause. The fact that a fault and/or uOp assist has to occur, and that AMD + ARM don’t have this issue is a hint that it’s a uArch issue at hand. It’s alluded to slightly in Section IV that every “first” load in the recovery path of a fault is used:
Specifically, when executing Line 6, the CPU speculatively loads a value from memory in the hope it is from our newly allocated page, while really it is in-flight data from the LFBs belonging to an arbitrarily different security domain.
I’d gander that, under normal architectural conditions, the typical pathways and FSM logic to mux the various load-return values incorporate all the typical permission checks and prioritizations. However, whether it’s due to a page fault or a good old flush, this logic is more or less “turned off”, whether as power savings or small perf gains, and whatever garbage result from the mux is simply returned. Remember, this was discovered in mid-2019, when the whole “who cares what happens before retirement” philosophy was rampant.
It’s impossible to say for sure, but feel free to message me with your own speculation. This hypothesis I have might also be why the next attack Zombieload is relatively distinct enough from RIDL, given the multi-facted multi-muxed nature of the Fill Buffers.
Zombieload
https://zombieloadattack.com/zombieload.pdf
Fallout
https://mdsattacks.com/files/fallout.pdf
Basically RIDL but with store->loads lol (though RIDL also included store->loads, but utilizing the Fill Buffer)
Fun fact– MemJam was basically a rather fishy precursor to this and was incredibly close to discovering it as well.
LVI
CrossTalk
https://download.vusec.net/papers/crosstalk_sp21.pdf
LazyFP
Floating Point Value Injection
Downfall
https://downfall.page/media/downfall.pdf
Pacman
Other?
These attacks are arguably not traditionally speculative in nature, but noteworthy.
Hertzbleed
https://www.usenix.org/system/files/sec22-wang-yingchen.pdf
Take-A-Way
I See Dead uOps
https://www.cs.virginia.edu/venkat/papers/isca2021a.pdf
Augury
https://lock.cmpxchg8b.com/zenbleed.html
Meltdown Warning signs
https://cyber.wtf/2017/07/28/negative-result-reading-kernel-memory-from-user-mode/
-
W. Xiong and J. Szefer https://dl.acm.org/doi/pdf/10.1145/3442479 ↩︎